March 4, 2025
Note - This is my edited work log, it is not comprehensive or instructional. If you need help with anything like this, email me!
Dan
I'm working on a project called <yes>tag which uses LLMs to generate code for some of the features it provides. As I was nearing the date of a live demonstration, the generative steps were failing to produce consistently impressive results. I was going to have a very bad demo.
This is a blog post describing the thought process I went through to resolve this issue as quickly as possible, with as little waste and most value created as I could. I used Cursor's Composer to generate task-specific evals for my ailing use-case, and surprised myself both with how effective task-specific evals were at improving my program, and how well "vibe coding" with Cursor could work for me, at least in these circumstances.
My prototype's LLM-powered functionality was not producing consistently acceptable output. The initial approach to artifact generation did not contain adequate controls to guarantee quality, resulting in unacceptable final output (around 1 in 6 to 1 in 8 success) and fragility in the source code and prompts.
Without resolving this problem, this project would not be useful enough for end-users. It wouldn't be reducing the skill floor to achieve production-ready web apps, only shifting the complexity from coding knowledge to "how to prompt <yes>tag" knowledge - not the big win for the problem space I'm hoping for.
I used Cursor to rapidly create a task-specific eval tool for controlling quality of <yes>tag's form building use case, and improve outputs significantly. The tool greatly simplifies testing a wide range of cases that can appear in the space of combinations of form fields, html structure and css/style specifications. It took about 5 days to create the evals, unit tests, web app, test data, use it all to optimize the program into production readiness, and confidently demonstrate the application to a prospect.
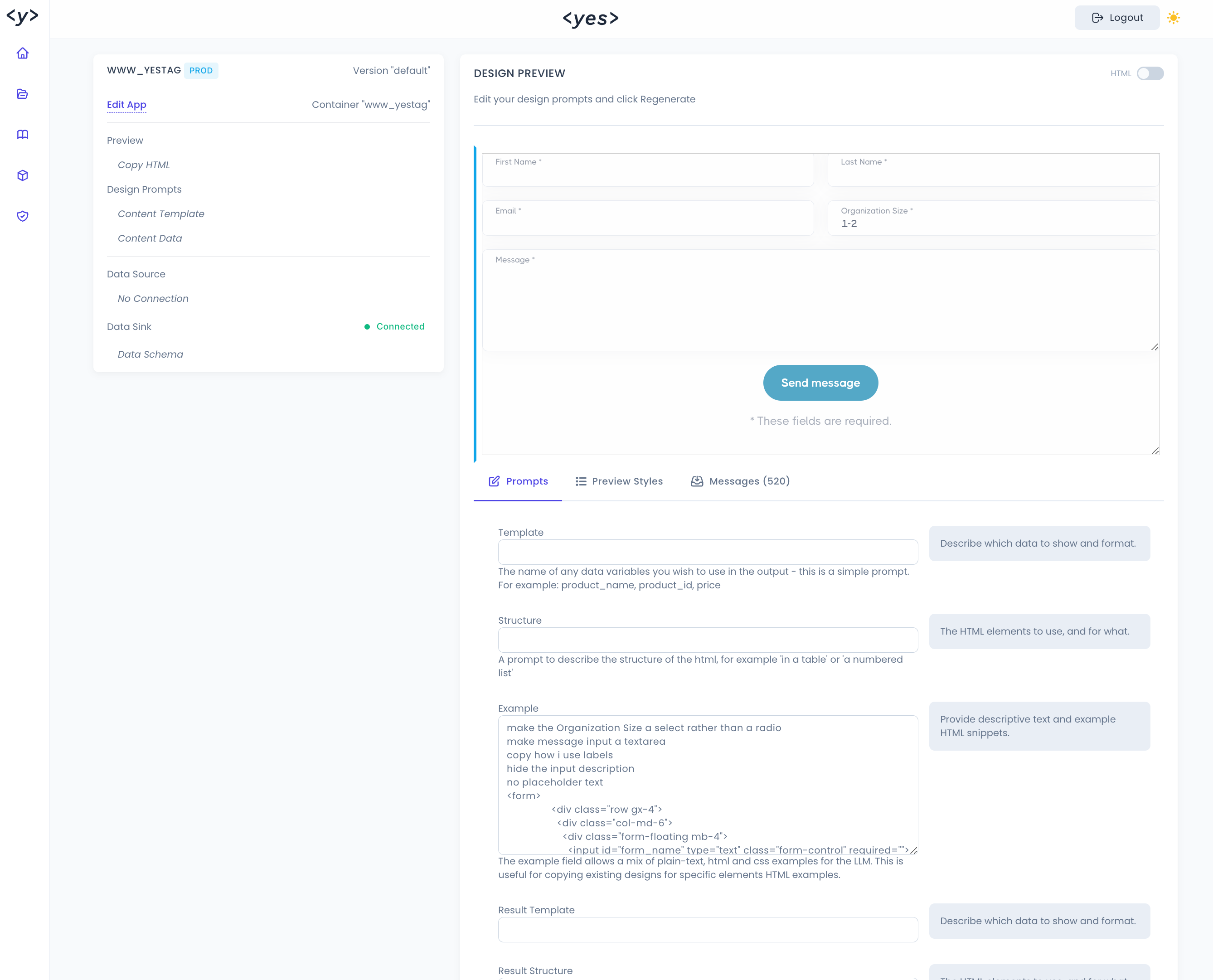
It works by supplying OpenAPI specs in a jsonl file, a file for the Example prompt (html snippets and plain-language instruction), which are input to the LLM-powered generation step, with output stored in a results jsonl file. This file is accessible in a viewer web application (FastAPI, HTML, vanilla js) which was generated using Cursor. The web application's GUI makes it easy for me to browse the result outputs, add my human evaluations, and then view the Accuracy, Reacall, False Positive and False Negatives of the eval prompt. The end result is that I have a simplified and structured process to view the results of a range of inputs, understand the performance of the prompts in my pipeline, keep a record of test scores over time. and ultimately the power to rapidly test new LLMs and prompt changes without drowning in complexity.
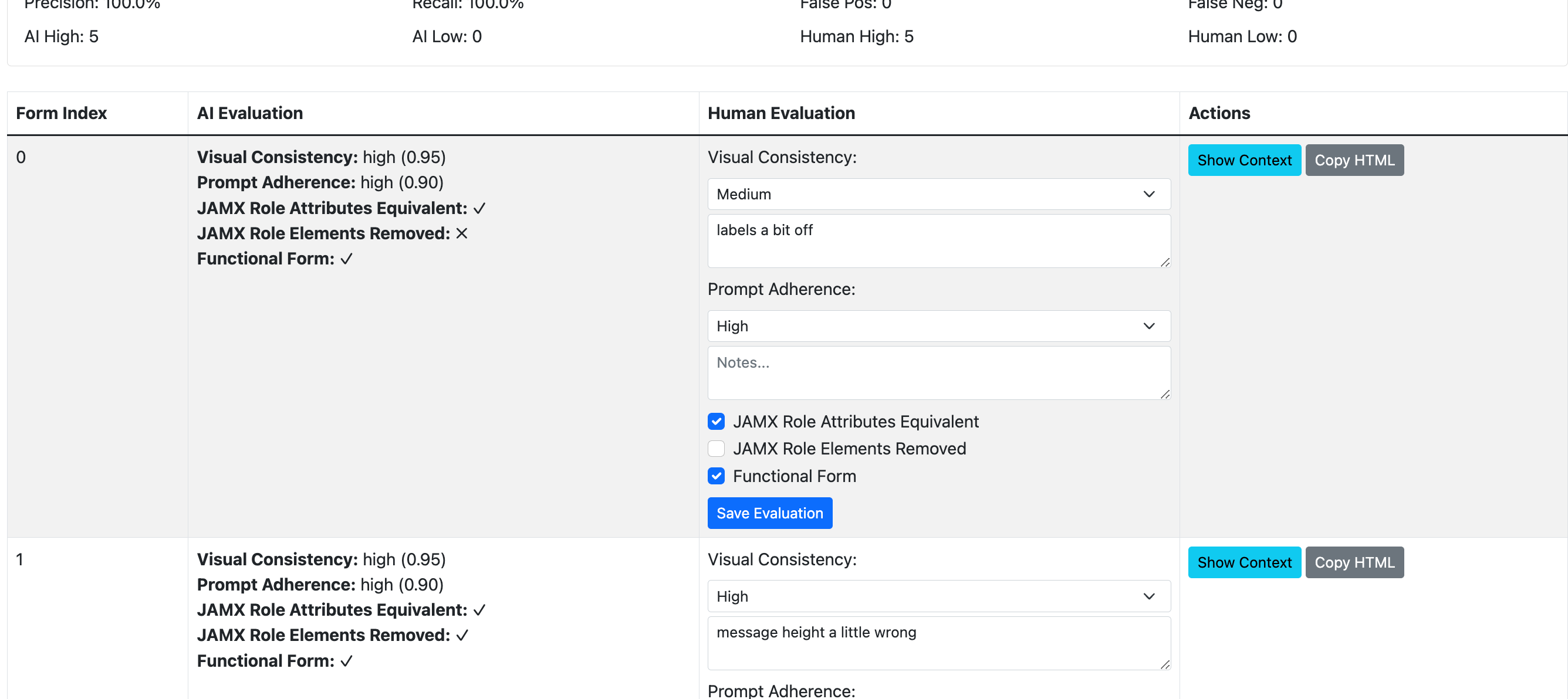
After using the tool to improve the prompts, find a better language model, and develop a new "judge" process for the use-case, I'm seeing a 100% success rate (instead of approx. 1/7), and the time required to create a production ready form has changed from at least 30 minutes (and many attempts and tweaks) on average to 1-2 attempts and around 3-6 minutes consistently. My eventual goal is completely removing the need for a human judge, which may require additional automated testing techniques such as using screenshots (multi-model) and automated browser testing.
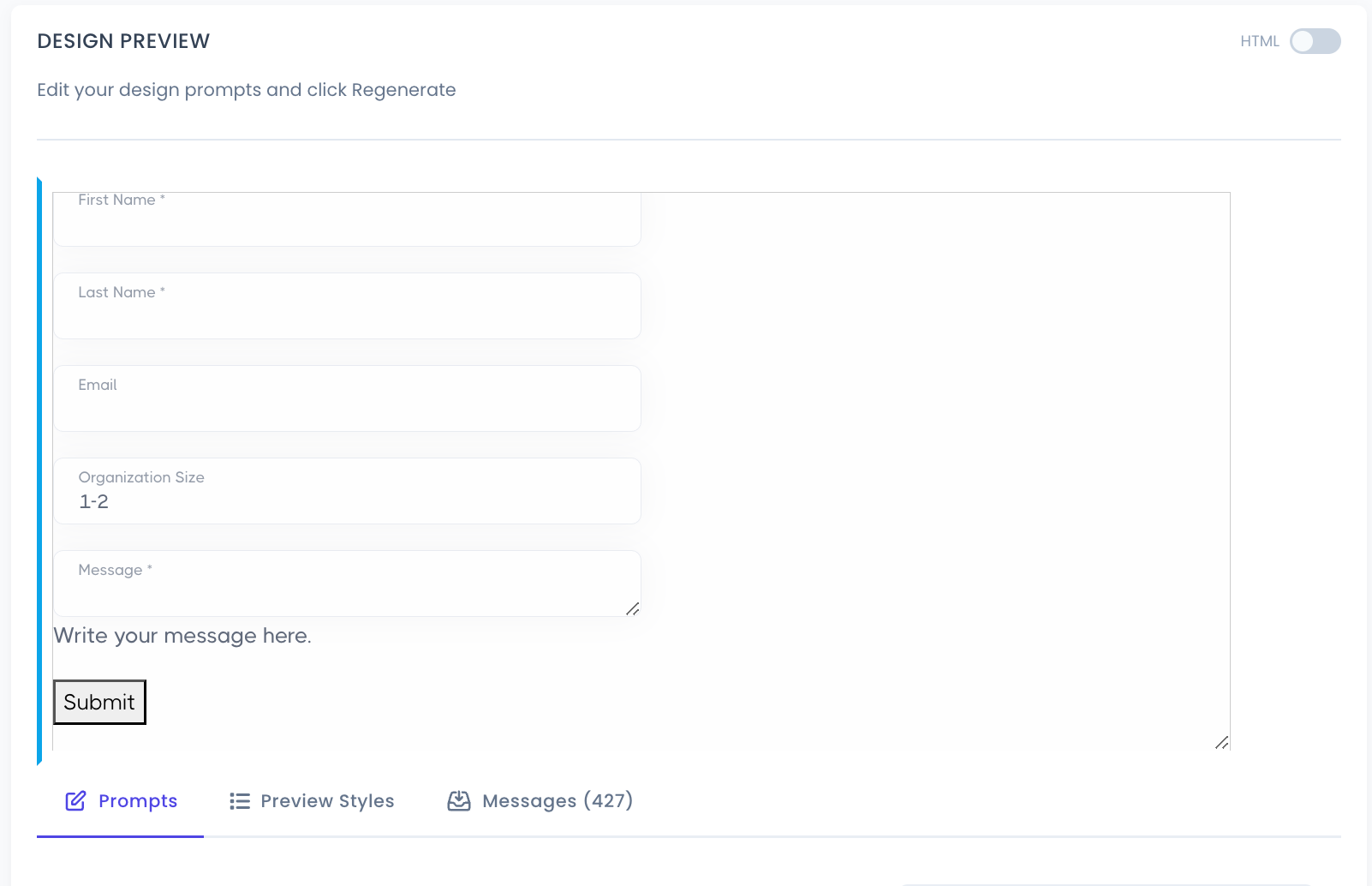
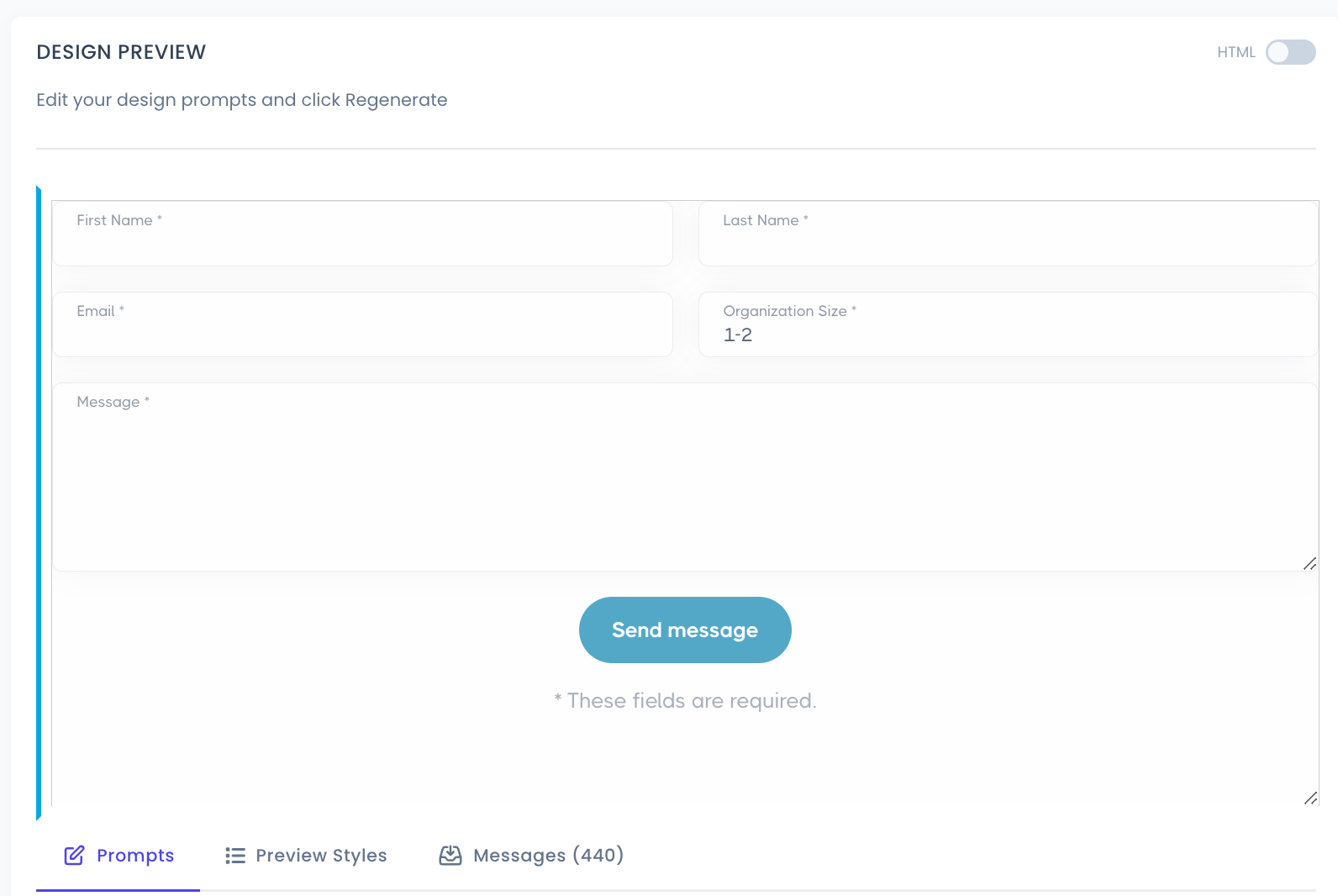
My service <yes>tag creates production-ready web forms that match the design and styling of existing websites or style guides/html templates. The forms are fully functional, submitting their data to any REST API endpoint. Our end-users are not expected to be web developers, nor have experience with editing code or using chatbots. My goal is to enable a broad spectrum of end-user skillsets, from designers and developers to marketers or product managers, to rapidly create and deploy production-ready web application components in minutes, with a low skill-barrier to success.
In the world of LLMs, Evals are currently most often discussed from the base-model perspective, where the many emerging LLMs are compared against each-other using various evaluation suites (MMLU, HumanEval, etc). Within the context of an application using LLMs for enabling features, evals are needed at the task level - the level of a specific prompt, or chain of prompts, that achieve a specific result for your application.
I think of task evals as spiritually similar to a unit or integration test, but more necessary. It's less intuitive to understand the exact behaviour of the non-deterministic unit being tested, and less predictable than imperative code, meaning it's a less dependable piece of your program by nature. By creating task evals, automating testing using them, and even using the evals within the flow of your application (like in <yes>tag's multi-agent system), you can improve your software's quality for maintainers and end-users alike.
It's useful to adopt techniques and measures (like Accuracy, Precision, and Recall) commonly used by AI practitioners to judge their model performance, which has emerged as one of the most important aspects of building applications with LLMs. It has been said that "evals are surprisingly often all you need" (Greg Brockman, CoFounder OpenAI) which is a growing sentiment, with an equally growing negative sentiment against "vibe checking" which is just looking at the results a few times. Vibe checking worked for me during the prototyping phase of building out <yes>tag, but ultimately was a procrastination I don't recommend you repeat. The benefits of a structured evaluation habit are realized very quickly.
Ideally, you can create evals for every prompt/interaction your application has with an LLM. However, for my current project and my resource/time constraints, I've opted for a higher level of granularity, by evaluating the output of a handful of LLM calls chained together. I will be looking to cover all prompts individually, as well as all chains, as the project progresses.
There are a number of ways to create an eval. Good writing on this subject is being done by Eugene Yan (https://eugeneyan.com/writing/evals) and others. My problem boils down to a classification/extraction problem: I need to rate output, rank attempts, and ensure some operations are completed without error/hallucination.
I performed a series of interactive code editing sessions with the Cursor Composer, set to claude-3.5-sonnet.
(There were roughly 12 composer sessions with one or more interactions)
I ended up with a very useful piece of testing/development functionality that only took a couple days of effort to see large benefit from. The circumstances of my needs were favourable for success with code generation.
The effort-to-value ratio here was high, and I was able to keep most of the generated code decoupled from the rest of my systems, making it easier to dispose of if I decide to start again or switch to a good framework/product when I'm ready. I feel this is an example of a changing build vs. buy equation, as this took much less time than it would have taken to choose from a SaaS tool or framework and implement it, at a disposable cost. The "generate vs. hand-code" equation here was clearly in favour of Cursor, given the context switch, various framework + library refreshers I would have to do plus ~3-4k new lines of code.
Evals are good! They should be called goodvals.
Use Cursor if you're confident in your domains, but check out things like Helicone and Langfuse if they're suitable. There are many emerging methods for this type of work.
There's no way you read all this. Thanks!